Project Portfolio
ACI SpeechHub
Keywords: NLP, ASR, Diarization, YouTube to Doc
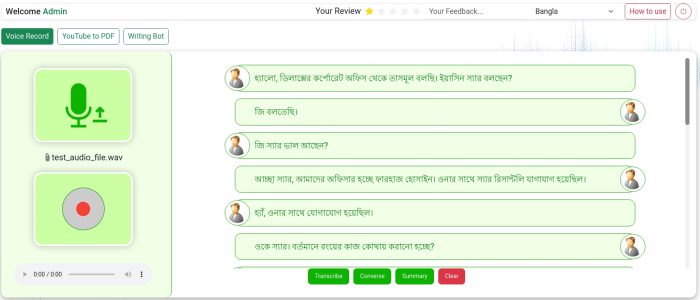
ACI SpeechHub is a combination of several audio based applications developed for meeting automation, call centre automation and several other business usage. The entire ML backend was developed by me integrating models for speech recognition, speaker diarization, dialogue summarization and keyword detection.
Key Features of ACI SpeechHub:
- Incredibly low-latency (approximately 50s for 1 hour of audio) Audio Transcription in Bengali and English languages.
- Speaker Diarization and dialogue-style conversation generation from audio data.
- Summarization of entire conversation.
- Mentioned keywords detection and frequency count.
- YouTube to PDF generation.
Key Technologies used in ACI SpeechHub:
Transformer-based (Whisper-Medium) Automatic Speech Recognition (ASR) system.
Flash attention 2.0 based Insanely Fast Whisper technology used for incredibly low latency transcription.
Integration with PyAnnote based speaker diarization for dialogue style conversation generation.
BERT based dialogue summarization technology.
Levenstein distance based Keyword detection system.
Integration of FastAPI based devOps system and SQL based database system for seamless usage.
- Backend language: Python 3.9, PyTorch
The code for this project can't be made public for security reasons, but can be provided with proper check. Contact me via Email if you needed.
Face Recognition and Live Attendance System
Keywords: Deep Learning, Face Recognition
The face recognition based live attendance system uses IP camera in the office compound to detect faces of employees and generate automated attendance system. Each registered employee's face is detected and then the entry and exit time is written in the database. The database further can calculate total office hour spent by an employee from the recorded system.
Key technology used:
FaceNet architecture based face recognition system.
Anti spoofing system for detecting false positives.
Qdrant based vector database system for storing and later matching facial embeddings of employees.
Backend language: Python 3.8

Document Keyword Extraction for Supply Chain PO & PI Documents
Keywords: Deep Learning, Document Extraction, Prompt Engineering
Important information extraction from supply chain PO and PI documents using Google's multimodal "Gemini" model with proper prompt engineering. The problem statement was to fill in business forms by extracting several important information such as "Importer/Exporter Name", "Bank Details" etc. from supply chain documents.
Key technology used:
- Google’s Gemini 1.5 Flash API based service.
- Prompt Engineering by experimenting with several types of prompts.
- Backend Language: Python 3.8

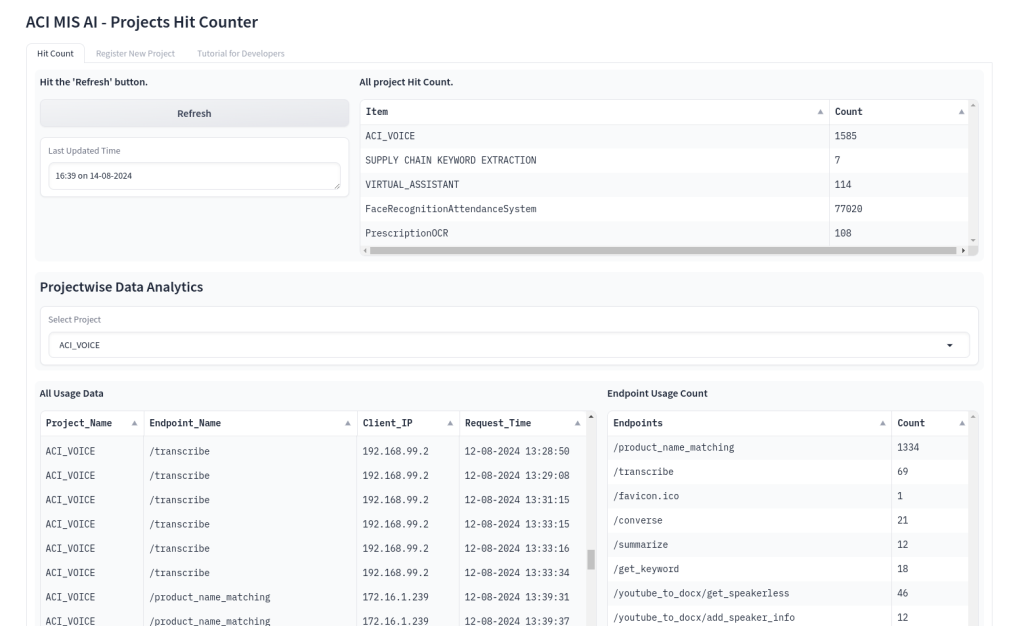
ACI Project HitCounter
Keywords: DevOps, Logging System. Gradio
The ACI Project HitCounter is a project developed for documentation of each project usage among the businesses. This project interrupts each API requests in the ACI servers and creates a log file. Later, the frontend reads the logfile for a comprehensive overview of each project usage with count of total project usage as well as count of each endpoint requests.
Key technology used:
- API middleware to interrupt API requests of each projects and create logs.
- SSH technology for server-to-server communication.
- Gradio for frontend.
- Backend Language: Python 3.9
Bangla NLP Toolkit - PyPi Package
Keywords: NLP, Deep Learning, PyPi
BanglaNLPToolkit is a package for several classic NLP text preprocessing and augmentations for Bangla NLP tasks.
Key features:
- Bangla Text Normalization.
- Bangla text unicode normalization for text preprocessing using bnunicodenormalizer and csebuetnlp/normalizer.
- Removal of punctuations or replacement of punctuations with desired sign as user desires.
- Bangla Punctuation
- Add punctuations to Bangla texts with no punctuations.
- Uses deep learning based Named Entity Recognition models for accurate punctuation addition.
- Bangla Text Augmentation
- Text augmentation techniques for generating similar but different texts for augmenting Bangla dataset.
- Uses paraphrasing, cross translation and masked word prediction algorithms for augmented text generation.
- Simple Bangla Tokenizer
- Robust simple word level tokenizer for Bangla texts.